

Varje CCM-plattform — oavsett om det är opentext Exstream, Quadient inspire eller SMART Communications — har samma dolda risk inbyggd: en liten ändring i en mall, en datamappning eller en konfigurationsinställning kan tyst förstöra dussintals dokument i efterföljande processer. Ändringen går live. Ingen märker det förrän en kund ringer, eller en revisor frågar varför deras utdrag ser annorlunda ut detta kvartal.
Detta är inte hypotetiskt. Det är ett av de vanligaste – och mest undvikbara – problemen i CCM-produktionsmiljöer. Och lösningen är inte mer manuell kontroll. Lösningen är automatiserad regressionsprovning av CCM.
Den manuella testfällan
De flesta CCM-team har en testprocess. De granskar utdataexempel före en release, jämför PDF-filer sida vid sida och går igenom en checklista. Det fungerar – tills det inte gör det.
Manuell testning har tre grundläggande problem i ett CCM-sammanhang:
- Det skalar inte. En CCM-miljö kan generera tusentals dokumentvarianter över segment, språk, kanaler och affärsregler. Ingen checklista täcker alla.
- Det är inkonsekvent. Människor missar saker under tidspress. Samma test utfört av två olika personer ger olika resultat.
- Det skapar ingen revisionsspår. När något går fel kan du inte enkelt bevisa vad som testades, när eller av vem – vilket är av stor betydelse i reglerade branscher som finansiella tjänster, försäkring eller energibolag.
Frågan är inte om din CCM-utdata någonsin kommer att gå sönder. Frågan är om du kommer att upptäcka det före eller efter dina kunder gör det.
Vad regressionstestning faktiskt skyddar
Regressionsprovning i en CCM-miljö handlar inte om att hitta uppenbara buggar. Det handlar om att upptäcka den subtila förändring som ackumuleras över tid: ett fält som tidigare renderades korrekt trunkeras nu, ett villkorligt block som aktiveras när det inte borde, en PDF som ser rätt ut på skärmen men inte uppfyller tryckproduktionsspecifikationen.
Mall- och utdataintegritet
Varje gång en mall redigeras — även en mindre textändring — bör hela dokumentfamiljen den tillhör valideras. Automatiserade tester jämför nya utdata med godkända baslinjer och flaggar alla avvikelser, inklusive layoutförskjutningar, saknat innehåll och ändrad formatering.
API- och integrationspålitlighet
CCM-plattformar lever inte isolerat. De tar emot data från ERP-system, CRM-plattformar och integrationslager. Automatiserade API-tester validerar att de anslutningar dina dokument är beroende av returnerar rätt data, i rätt format, med rätt autentisering – före varje driftsättning.
Kanalspecifik validering
Ett dokument avsett för utskrift har andra krav än ett som levereras via e-post, portal eller Kivra. Regressionstester kan anpassas per kanal och fånga upp problem som endast uppstår i specifika utdataflöden.
Automation förändrar ekvationen för releaser
En av de vanligaste anledningarna till att CCM-team motstår automatisering är installationskostnaden. "Vi skulle spendera mer tid på att bygga testerna än att köra dem manuellt." Denna kalkyl förändras snabbt när du tar hänsyn till den verkliga kostnaden för alternativet: en release som bryter något i produktion, en helg som ägnas åt att diagnostisera och återställa, och den ryktesmässiga kostnaden för felaktig kundkommunikation som skickas ut i stor skala.
Automatiserade regressionstester, när de väl är byggda, körs på några minuter. De körs konsekvent varje gång. Och de ger processägare och produktägare något genuint användbart: en tydlig godkänd/ej godkänd-status innan ett releasebeslut fattas. Inte en lista över saker som kontrollerades, utan ett verifierbart resultat.
För organisationer som kör regelbundna CCM-releaser — månadsvis, varannan vecka eller snabbare — är detta skillnaden mellan en releaseprocess som känns kontrollerad och en som känns som en chansning.
Hur en mogen CCM-testpraxis ser ut
Organisationer som har investerat i automatiserad regressionstestning för CCM delar vanligtvis några egenskaper:
- Testfall är versionskontrollerade tillsammans med mallar och konfigurationer — ändringar i det ena utlöser en omkörning av det andra.
- Testkörning är en del av driftsättningspipelinen, inte ett separat steg som kan hoppas över under press.
- Resultaten lagras med tillräcklig detaljrikedom för att stödja granskningar och efterlevnadskontroller — inte bara godkänt/ej godkänt, utan vad som testades, vad det förväntade resultatet var och vad det faktiska resultatet var.
- Icke-tekniska intressenter — processägare, efterlevnadsansvariga, affärsgodkännandekontakter — kan läsa och tolka testresultaten utan att behöva en utvecklare för att översätta dem.
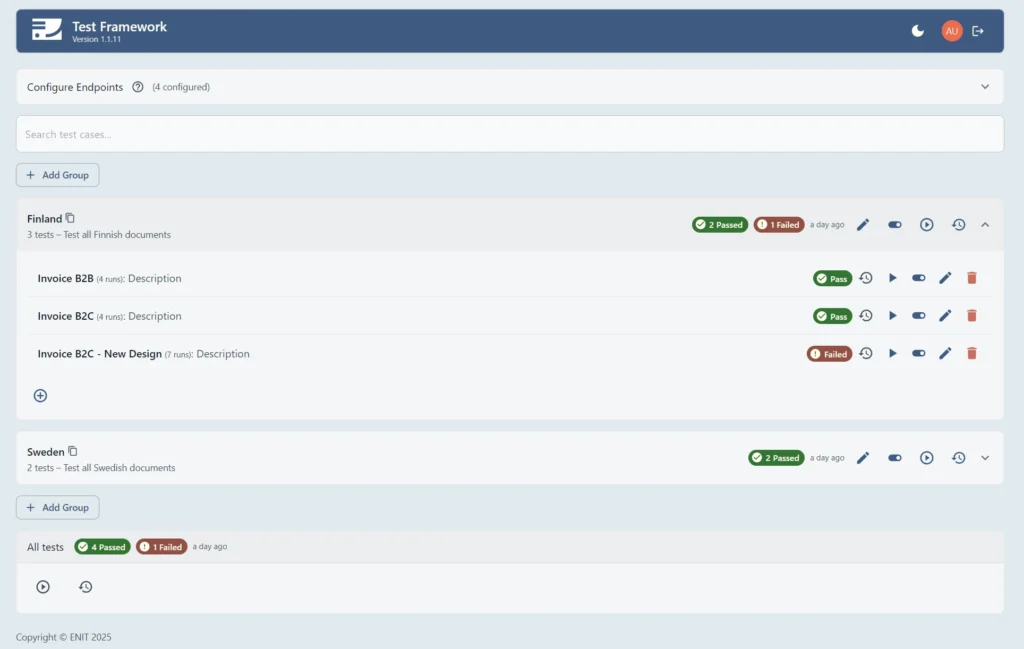
Här är ENIT Test Framework-panelen som visar automatiserade CCM-testresultat.
Var man ska börja
Du behöver inte automatisera allt på en gång. En praktisk utgångspunkt:
- Identifiera din dokumentfamilj med högst risk — den där ett fel skulle ha störst inverkan.
- Definiera hur "korrekt" utdata ser ut för en representativ uppsättning testfall.
- Bygg en liten automatiserad testsvit kring den familjen och kör den mot din nästa planerade release.
- Utöka täckningen progressivt, prioritera efter volym och regulatorisk känslighet.
Målet i den första fasen är inte fullständig täckning. Det handlar om att etablera vanan och verktygen – och att visa organisationen att förtroendet för releaser inte behöver komma från hopp.



